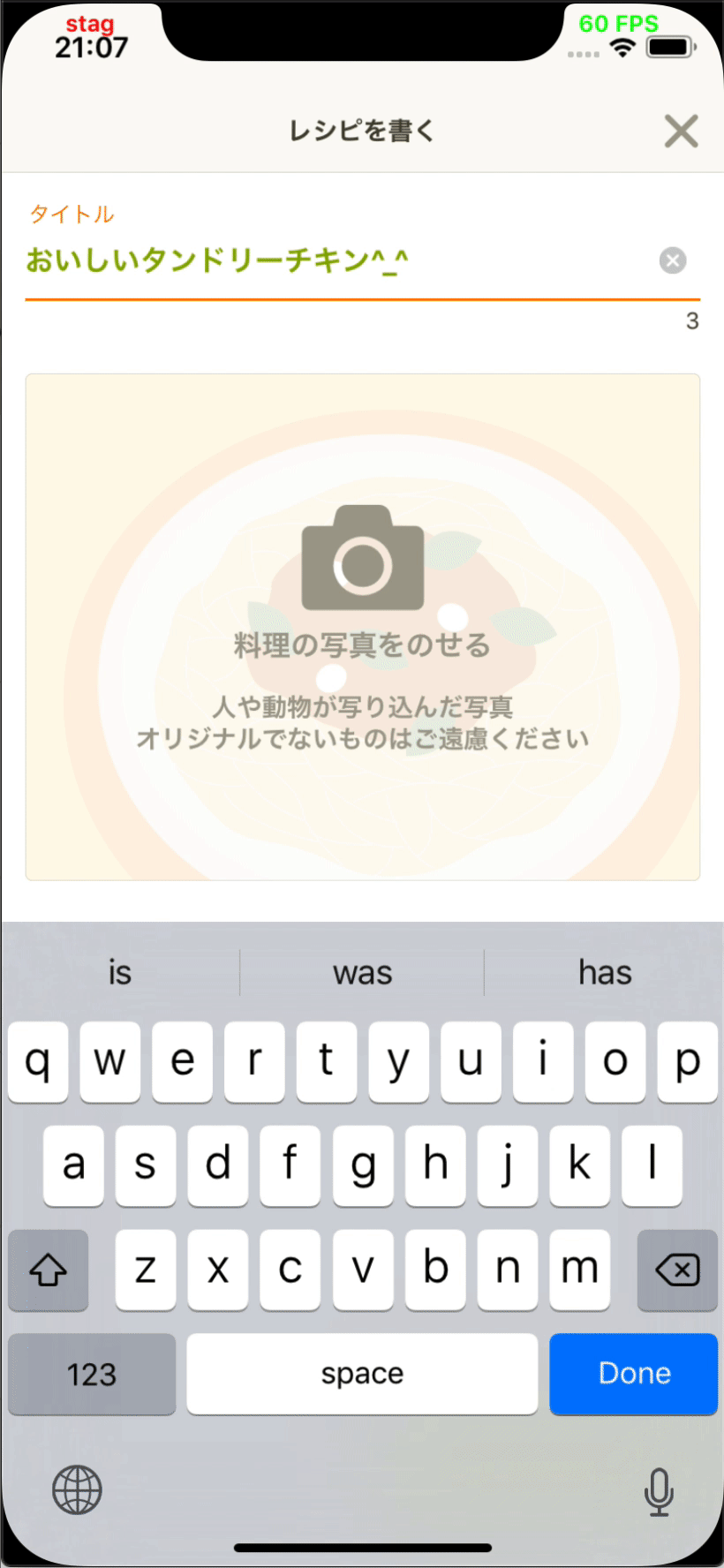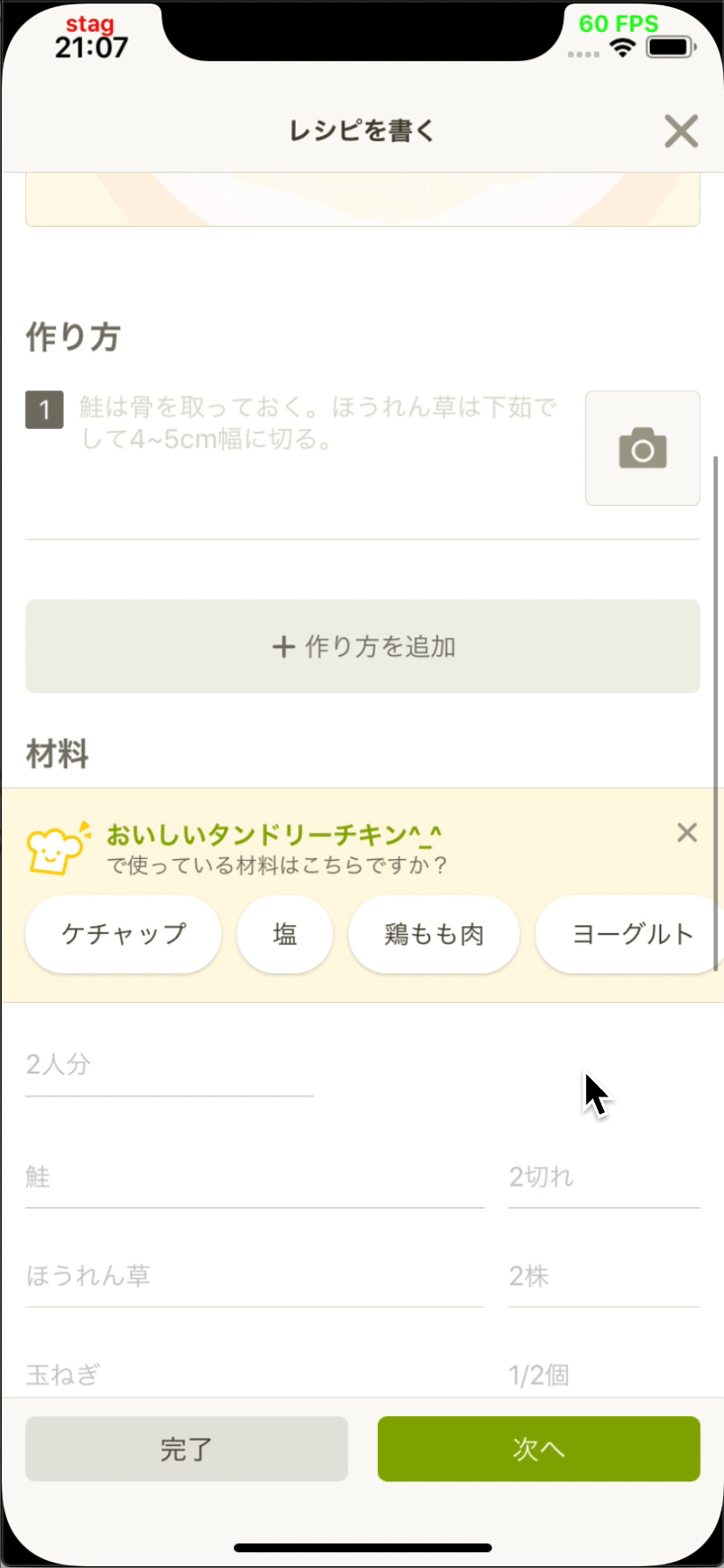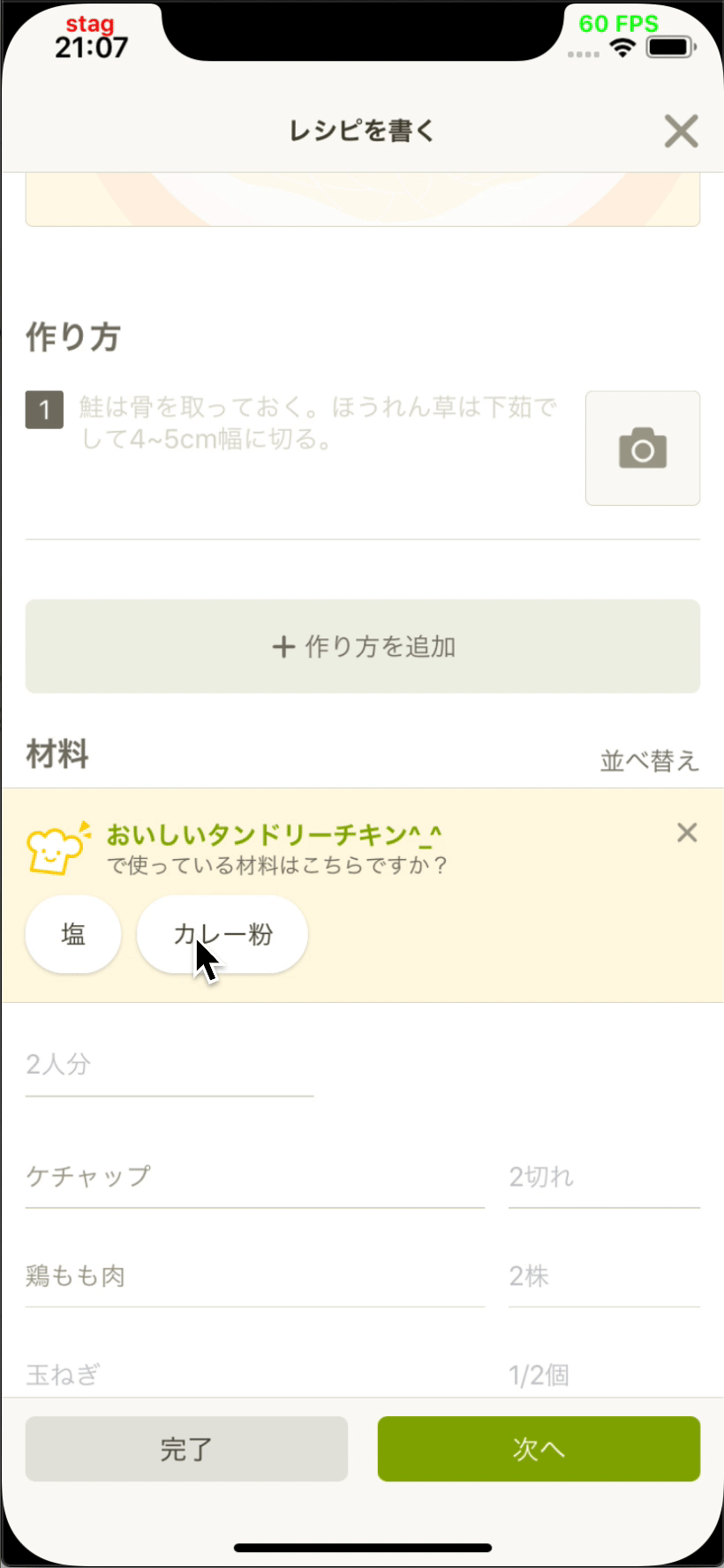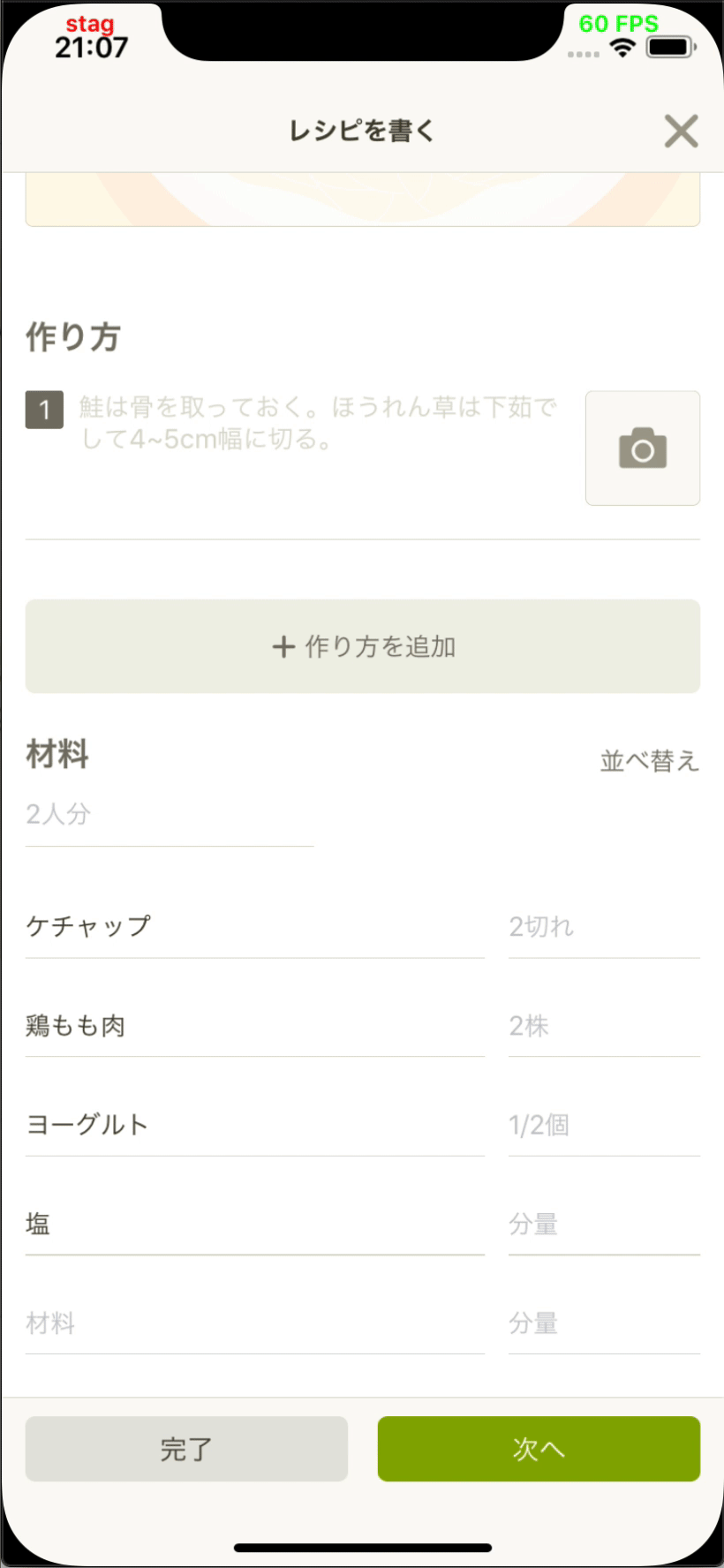
インフラストラクチャー部の青木峰郎です。 最近はDWH運用の傍ら、所属とまったく関係のないサービス開発のためのデザインスプリントをしつつ、 Java 10でgRPCサーバーを書きつつ、 リアクティブプログラミングを使った非同期オーケストレーション層を勢いだけで導入したりしています。
ですが今日はそれとはあまり関係なく、クックパッドの中核サービスであるレシピサービスの アーキテクチャ改善プロジェクト、「お台場プロジェクト」の戦略について話します。
これまで、お台場プロジェクトで行った施策について対外的に発表したことはあっても、 全体戦略について話したことはありませんでした。 その一番の理由は、正直に言って、プロジェクトオーナーであるわたしにもプロジェクト全体の姿が見えていなかったからです。 しかし現在プロジェクト開始から1年半が経過してようやく全貌が見えてきたので、すべてをお話ししようと思います。
クックパッドの「本体」システム
クックパッドは現在では大小様々なサービスをリリースしています。 しかしその中でも最初期から存在し、 現在でもあらゆる意味で中核にあるサービスがいわゆる「クックパッド」、 社内では「本体」や「cookpad_all」さらに略して「all」などと呼ばれているレシピサービスです。
このレシピサービスは世界最大のモノリシックなRuby on Railsサービスであり、 いま手元で適当に数えただけでRubyのコードが27万行(テストを除く)、 テストが51万行、HTMLテンプレートが14万行あります。 このコード量でウェブサービスのcookpad、APIサーバーのpantry、 バッチのkuroko、管理画面のpapaの4アプリケーションを主に実装しています。
お台場プロジェクトとは
そして、この巨大な「本体」システムのアーキテクチャを根本から刷新し、 改善するプロジェクトが「お台場プロジェクト」です。 わたしがこのお台場プロジェクトを開始したのは去年(2017年)のバレンタインデー、2月14日のことでした。 そのときやったことは「とりあえず改善したいことをリストアップする場所」としてGitHubにレポジトリを作っただけでしたが、 その後にお台場プロジェクトは技術部の注力課題に昇格してメンバーも大幅に増員され、1年半が経過しました。
約30万行というコードサイズは世間一般で言えば超巨大とは言えないでしょうが、 少なくとも容易なプロジェクトではないことは確かです。 2017年2月の時点では、このプロジェクトを達成できると言う人も、俺がやると言う人も社内にはいませんでした。 むしろ、本体には関わりたくない、できるだけ触りたくない、 最低限の機能追加以外の余計なことはしたくないという雰囲気が充満していたように思います。
お台場プロジェクトが目指すもの
お台場プロジェクトの目的は、「本体」にも大規模な機能追加・変更ができるようにすること、 さらにその大規模な変更をできるだけ少ない時間でできるようにすることです。 逆に言うと、プロジェクト開始時点では、思い切った機能追加はできなかったということになります。
大規模な変更を行えない技術的な理由としては以下のような点が挙げられます。
- コードを変更すると意図しないところが壊れる。例えばウェブサービスをいじるとガラケーの認証が壊れる。
- ライブラリが古かったとしても依存が多すぎて気軽に更新できない。
- 実行環境が非常に複雑かつ特殊で、迂闊にデータベースを追加したりできない。
- 普通のツールが動かない。例えばコードカバレージが取れない、並列テストが動かない。
- ObjectクラスやStringクラスのような非常に基本的なクラスが改変されており、普通の動きをしない。
また、組織的・プロセス的な理由もあります。
- あるコードのオーナーが誰かわからない。例えばuserリソースのAPIを変更したくても誰にも相談できない。
- GitHubのissue・pull requestが多すぎてとても全部は見ていられない。通知も何も機能しない。
- 「本体」をいじる開発者が多すぎて、改善系のpull requestを作ると頻繁にコンフリクトする。
「本体」で大きな変更を行おうと思うと、これらの問題がすべて同時に襲いかかってきます。 例えばI/Oの激しいシステムを追加するためにDynamoDBを使いたいと思ったとしても、 AWS-SDKのバージョンが古いのでまずはSDKのバージョンを更新するのに1ヶ月かかる、 テストが遅いので検証にも時間がかかり、そのあいだに別のpullreqがマージされてコンフリクト、 実装を進めていくと既存のクラスに変更が必要そうなことがわかってきたがオーナーが誰かはわからない、 がんばって実装してみたが触ってもいないバッチのCIが通らない、 ようやく理由がわかって直してデプロイしたらなぜかガラケーサイトが落ちた……という具合です。
これはさすがに誇張だろうと思われるかもしれませんが、残念ながらすべて事実を元にした話です。 こんな開発を続けていれば、大きな機能を追加しようという気がなくなって当然でしょう。
タスクの優先順位の決定
こんな状態ですから、なんらかの改善をしなければいけないことはわかります。 しかし、はたして何から手を付けたらよいものでしょうか。 まずは問題をリストアップしてはみたのですが、あまりにも問題が多すぎ粒度もバラバラ、しかもどれも大変そうで腰が引けます。 タスクを絞るところが肝であることはどう考えても明らかでした。 そこで、ビジネス上の価値と政治的判断を加味しつつ、「やること」「やらないこと」を次のようにエイヤと決めました。
やること:
- APIサーバー(pantry)のアーキテクチャ改善
- 不要なサービスの廃止
- デッドコードの自動検出と削除
- ストレージ数の削減
- 特殊な実行環境・開発環境の廃止
やらないこと:
- ウェブサービス(cookpad)のビュー改善
- Railsのメジャーバージョンアップ
- 細かい実装レベルの改善
最初に決めなかったこと:
- 全面的にmicroservice化するかどうか
まず、ユーザー数と有料会員数の分布、将来向かう方向を考えると、 ウェブやガラケーよりもスマホアプリのAPIサーバー(pantry)が重要であることは明らかなので、 そのアーキテクチャ改善につながらないタスクは原則捨てると決めました。 そうすると例えばウェブのビューの実装改善などは自動的に「やらないこと」になります。
microservices化はギリギリまで先送り
一方で、先に述べたように、本体のコードはオーナーがよくわかりませんし、 最初からmicroservices化するとは決断できなかったので、 いきなりそこに大々的に踏み込んでいくことはしませんでした。 例外は検索システム1つだけです。
最終的にコードをなにかしら分割することは避けられないとは思っていましたが、 サービスとして分割する以外にも、たとえばRails engineとして分割するなど代替案はいくつかあります。 とにかく戦略的に、大々的に分割するぞーと宣言して分割はしたけど失敗でしたという事態だけは絶対に避けたかったので、 どうしても分割を避けられない時が来るまで決断を遅らせることにしたわけです。
これほど慎重になった背景にはもちろん理由があります。 実は、クックパッドでは2015年から2016年くらいにすでに一度microservices化を試して失敗した経験があるのです。
当時はmicroservices化の機運が社内で盛り上がっており、 今後「本体」に機能を追加するときは必ずmicroservicesに分けようということになりました。 しかしこのときの経過が非常にまずくて、業務プロセスを複数のアプリに分断してしまって作業が増えたり、 管理アプリだけ別サービスに分割したことによってひたすら新規APIを作るはめになったりと、 microservices化全般に悪い印象だけが残ってしまったのです。 後者の管理アプリに至っては最終的に「本体」の管理アプリに統合され、microservicesではなくなってしまいました。
この時の経験があったため、最初からシステム分割を行うのはできるだけ避けることにしました。 最初に社内のエンジニアにお台場プロジェクトの話をしたときも、 microservices化に反対する意見が出た場合に備えて想定問答集を作ったほどです。 もっとも実際に話してみると、当時とは社内外の状況が変わったこともあって、反発はほとんどありませんでした。

ちなみにそのときの写真がこれで、わたしが用意した大変わかりやすいスライドで成田CTOが喋っているの図です。 お台場プロジェクトが終わってからプレスリリースを打つときに使おうと思っていた秘蔵写真ですが、 いい機会なので公開します。
最初は確実に成果を出せるコード削除を実施
いきなりサービス分割をしない代わりにまずやったタスクが、古いサービスの廃止と、古いAPIサーバーの廃止です。 ほぼ誰も使っていない機能の廃止はトレードオフがほぼないので、どう考えてもやったほうが得であり、 しかも誰も反対しないからです。まず最初にわかりやすい成果を作るために最適のタスクでした。 社内に効果を示すためにも、チームが自信を得るためにも、 比較的簡単にできて結果のわかりやすいタスクから始めるのは妥当でしょう。 時期的にもちょうど大きな機能が分社されて消せるコードがたくさんありました。
また、今後コードを消していくうえで、 本番で使われていないコード(デッドコード)がツールで自動判定できたら非常に楽ができるので、 その方法を少し調べて実施することにしました。 その結果できあがったのがRubyのLazy Loadingを使って実行されないコードを探す手法です。 現在ではこのシステムによって自動的に不要コードを検知できるようになっています。 さらに、このデッドコード検出機能はブラッシュアップされてRuby 2.6にも取り込まれました。
「Railsのメジャーバージョンアップはしない」
Railsのメジャーバージョンアップもお台場プロジェクトではやらないと最初に決めました。 これは単純に「Railsをバージョンアップしたところでアーキテクチャの根本改善にはつながらない」 という理由もありますが、その他に一種のシンボル的な意味もあります。
この点を説明するには、まず少しだけクックパッドの組織構造の話をする必要があります。 クックパッドでは永らく、 「本体」のソフトウェアアーキテクチャ(主にRails)については技術部の開発基盤というグループが責任を持ち、 それより上の機能については各事業部が分割して持つという責任分担が行われてきました。 結果として2016年までの数年は、開発基盤グループに新しい人が入るととりあえず 「本体」のRailsバージョンアップをするというのが洗礼の儀式のように行われていたのです。 しかしこのタスクが技術的にも政治的にも非常につらく、 結果として若者が「本体」に対するヘイトをためていく構造になっていました。
そういった歴史の結果として、クックパッドにおいては「Railsのバージョンアップ」というタスクが 「これまでの開発基盤の役割」とほぼ同じ意味を持っています。 そんな状況で、開発基盤で新しいプロジェクトを始めます、 それじゃあまずRailsバージョンアップをやりますと言ったら、いままでと何も変わりません。 中身は同じで名前だけ変えたんですねということになりかねないからです。
お台場プロジェクトはシステムアーキテクチャの改善プロジェクトであると同時に、 組織アーキテクチャの改善プロジェクトでもあります。 巨大な1つのシステムをメンテするのはもはや手に余るので分割統治しよう、 というのがお台場プロジェクトの目的ですから、組織もいまのままであるわけがありません。 具体的には、開発基盤グループが不要にならなければいけません。
つまりある意味で開発基盤を解散させるプロジェクトでもあるお台場プロジェクトで、 これまでの開発基盤と同じことをやるというのはどう考えても筋が通らないわけです。 ですから、お台場プロジェクトでは絶対にRailsのバージョンアップはしないと決めました。
アプリケーション構造の整理
コード削除とほぼ同時にやったのが、アプリケーション構造の整理でした。
これについてはそもそも問題自体の説明が必要でしょう。 「本体」システムはウェブサービスやAPIサーバー、非同期ジョブ、 バッチなど複数のRailsアプリケーションからなるのですが、 そのうちAPIサーバーと非同期ジョブはウェブサービスの「モード」として実装されていました。 ウェブサービスを起動したとき、特定の名前のファイルが存在したら APIサーバーのエントリポイントが生えてAPIサーバーとして動くという、凄まじい実装がされていたのです。
プロジェクト開始から2017年いっぱいくらいにわたって、このものすごい実装を排除しました。 APIサーバー(pantry)は独立したアプリケーションとし、非同期ジョブ(background-worker)はバッチ(kuroko)に置き換えるなどして廃止。 同時に古いAPIサーバー(api, api2)を消したこともあり、アプリケーション構造はだいぶシンプルにすることができました。

全面的なmicroservices化を決断
当初はmicroservices化を前面に出すかどうかはまだ決めかねていたのですが、 現在はすでに全面的にmicroservices化することを決めています。 その決め手となったのは、最初に小さな機能を分割してみて、その効果が明白に感じられたことでした。
具体的には、スマホアプリのA/Bテストなどに使っているuser_featuresという機能を分割した時点です。 この機能はもともと技術部がオーナーでしたし、専用Redis 1つだけにアクセスする構造になっていたため、 政治的にも技術的にも都合がよかったのです。 そこでこの機能を分割してみたところ、分割したあとのほうが明らかにつくりがわかりやすく、 改善しやすくなりましたし、実際に改善が進みました。 誰が実装すべきかも明確で、それでいて他の部署の人間も逆に手を出しやすくなったと感じています。 やはりコード共有というのは「誰も持っていない」のではだめで、オーナーありきのほうがうまくいくなと感じます。
わたし個人としても最近、本体のAPIサーバー(pantry)にとある機能を追加するためにmicroserviceを1つ実装したのですが、 DynamoDBを中心としたアーキテクチャ設計からstaging環境・production環境の構築に最小の実装までを、わたし1人で1週間弱で終えることができました。 これはお台場プロジェクトをやっていなければとてもできなかったことです。 もし2016年時点のpantryでこれをやれと言われたら何ヶ月必要になっていたか予想できません。
すべてがHakoになる
もともとクックパッドではmicroservicesのためのインフラは整備されつつありました。 例えば次のようなアプリケーションやミドルウェアが稼働しています。
- Amazon ECS向けコンテナオーケストレーションのHako
- アプリケーションモニターのHako Console
- AWS X-Rayによる分散トレーシング対応
- Envoy proxyを使ったサービスメッシュ
さらに直近ではRubyのgRPCライブラリの置き換えなども行われています。 すでに新規のサービスはすべてこれらのインフラに乗っていますが、「本体」をどうするかだけはずっと宙に浮いた状態だったわけです。
2018年になって、「本体」もこの共通インフラに乗せると決めた時点で、話は非常にシンプルになりました。 現在では徐々にではありますが「本体」がHako化(コンテナ化)されつつあり、来年内の完了を見込んでいます。 社内のすべてのシステムがmicroservices構成になり、コンテナで動く状態が視界に入ったと言えるでしょう。
microservicesへの分割戦略
さて、microservices化を決断した場合、次に問題になってくるのが、「どこでサービスを切るか」です。 正直、これはシステム設計の話なので、パッケージをどう分けるか、クラスをどう分けるかと同じようなものであり、 決定的な基準がありません。
しかし、特に「本体」システムに限って言えば分割する場合の成功パターンがわかってきました。
そのパターンとは、データベースがすでに分かれている機能については、データベースを中心としてそれに紐付く部分を分割することです。 「本体」はRailsアプリケーションにしては珍しいことに、非常に大量のデータベースにアクセスしています。 database.ymlを見る限りだと、実に20以上のデータベースが接続されているようです。 これらのデータベースを、データベースとそれに紐付くコードをまとめて分割すると、 意味的にもデータフロー的にも無理がなく分割できることがわかりました。 これは冷静に考えてみれば当然と言えば当然なのですが、 このことに気付いてからは、「データベースが切れているならシステムも切れる」というわかりやすい基準ができました。
具体的には、Solrを核として分離したレシピ検索のシステム(voyager)、 専用Redisを中心として分離したA/Bテスト機能(user_features)、 専用Auroraをベースとして分離した「料理きろく」機能などがこのパターンでうまく分割できた例です。 今後もこのパターンに沿って、専用MySQLを持つブックマーク機能(MYフォルダ)や、 投稿者向けの統計機能(キッチンレポート)を分割していく予定です。 逆に、メインの一番巨大なMySQLに紐付いた機能群は最後に分割することになるでしょう。
microservicesに分割するという話になった当初は分割の基準がよくわかっていなかったので、 例えば「レシピのようによく使うリソースを最初に切り出すのがよいのではないか」 「事業部3つに合わせていきなり3つに分割しよう」などなど、様々な考えが錯綜していました。 その根底には、ひとまず切り出せそうな部分はいくらか見えているのだが、 それを順番に地道に分割していくくらいではいつまでたっても本丸のコア部分の分割まで至らないのではないか……という焦りがあったと思います。
しかし実際にやってみて最もうまくいった分割方法はやはり「データフローが明確に切れるところで切る」ことです。 慌てず騒がずデータフローを分析して、端から削り切るのが結局は最短の道だと思います。
大きな静的データの共有問題
microservicesへ分割していくうえで他に困ることの1つが「大きな静的データの共有」の問題です。 例えばクックパッドだとテキストの分析に使われている専用辞書がこれにあたります。 この辞書は検索サービスからも検索バッチからもレシピサービスからも、 その他ありとあらゆるところから頻繁にアクセスされており、 これを果たして単純に単体サービスとして分割してしまっていいものか難しいところでした。
『マイクロサービスアーキテクチャ』などによると、 このようなタイプのデータは原則としてはサービスにするよりデータとして配布してしまったほうがよいようです。 クックパッドでは偶然にも、この辞書をGDBM化してメモリに乗せる仕組みが少し前に入っていました。 そこでこの仕組みを利用して、GDBMファイルを各アプリケーションに配布することでひとまず解決をみました。
その後、GDBMファイルのバージョン問題にぶちあたって少し方式を変更したりもしましたが、 いまのところうまく動いています。
APIオーケストレーション層の導入: Orcha
microservices化に関する直近の試みはAPIオーケストレーション層「Orcha(オルカ)」の導入です。 オチャではありません。 これはわたしが勢いだけで入れてみたものなのですが、思ったより便利で驚いています。
OrchaはJavaで実装されており、 Spring ReactorとSpring Fluxをベースとしたリアクティブプログラミングを活用しています。 下図のようにリバースプロクシ(rproxy)とAPIサーバー(pantry)の間に入り、 pantryを含めたmicroservices群のAPIを統合して、スマホアプリ用のAPIを提供します。

オーケストレーション層を入れようと思った最初の動機は、 スマホアプリから複数のAPIを呼ぶレイテンシーを削減することでした。 しかし実際に入れてみていま感じている最大の利点は、 「本体」にさわらずに既存のAPIを拡張できるという点です。 アーキテクチャを改善していくうえで非常に便利な道具が一つ加わったと感じています。
例えばレシピを取得するAPIに新しい情報を差し込みたい場合であれば、 本体のAPIサーバーが返したJSONを加工して情報を追加することで達成できます。 ようするに、「高機能なJSON用sed」のような動きをしているわけですね。
今後の展開
お台場プロジェクトは来年2019年から、最終の第4期に突入します。 これから1年強は、本体を片っ端から分離しHako化するという正面対決になるでしょう。 最初はデータベースが分かれている機能から分離を始め、徐々にメインDBを切り崩します。
また、せっかくOrchaという新しい自由な遊び場ができたので、 それを活用してGraphQLの導入を試してみようと思っています。 ちょうどスマホアプリの側でもiOS, Androidともにアーキテクチャが刷新されつつあるので、 新しい仕組みを導入するにはいいタイミングです。
まとめ
本稿では、クックパッドの中核たるレシピサービスのアーキテクチャを改善する 「お台場プロジェクト」について、その戦略のすべてをお話ししました。 特に意識して行ってきたことは次のような点です。
- 意図的にこれまでとの違いを出すタスク選択
- 最初は成果の出しやすいコード削除から
- microservices化は小さく試して全面展開
- オーケストレーション層で展開の自由度を高める
現在のところプロジェクトの最大の問題は、とにかく人が足りないということです。 エンジニアは全分野で足りていないのですが、サーバー側は特に足りません。 Railsならまかせろ!な方にも、Railsブッ殺す!な方にも、 やりごたえのある楽しいタスクがありますので、 ぜひ以下のフォームから応募をお願いいたします。
https://info.cookpad.com/careers
Special Thanks 〜またの名を戦績リスト〜
わたしはお台場プロジェクトについてはあくまで戦略レベルしか関与しておらず、 実装レベルの判断は特に聞かれない限り担当者にすべて任せています。 その点で、お台場プロジェクトは個々のエンジニアの力量によるところが大きいプロジェクトであり、 ここまで来られたのはすべてメンバーのおかげと言ってよいでしょう。 この記事の最後に、各自が撃破したタスクを記して、終わりにしたいと思います。 なお、プロジェクト開始から2018年内までに完了したものだけを、だいたい時間順に列挙しています。
- 検索システム(voyager)分離: id:ganmacs
- pantry独立: id:everysick
- 特売・健康分離: id:hogelog
- API/API2廃止: id:hogelog
- background-worker廃止: id:shia
- A/Bテストシステム(user_features)分離: id:tomo_ari
- ログイン導線(shishamo)分離: id:moro
- ユーザー管理基盤(user_backend)分離: id:everysick, 大石
- Ruby 2.4化: id:ganmacs
- デッドコード自動検出: id:shia
- 料理きろく分離: id:shia, id:kazy1991
- バッチのHako化(コンテナ化): id:hokaccha
※書き忘れてるやつあったらすまん……