この特徴を生かして、Jetpack Compose における相互運用 API として用意されているAndroidView/AndroidViewBinding*3を用いることで、マートAndroid で画面を構成している Layout XML をそのままクックパッドAndroidで利用することで開発速度の向上を図っています。
select_stmt = 'select column_a, column_b from the_great_table; -- an awesome query shows amazing fact up'
bundle = QueueryClient.query(select_stmt)
bundle.each do |row|
# do some useful works
p row
end
以前はこれでうまくいっていたのですが、2020年4月に起きたSQS障害で影響を受けたことや、Queueryの構成が複雑化していたことなどもあり、もっとシンプルで頑健性の高い仕組みにできないかと考えられていました。
そこで、2020年にRedshift Data APIが発表され、そのAPIに含まれるexecuteStatementとdescribeStatementを利用すればBarbeque依存を外せそうだという案が上がりました。調査したところ非同期処理の周辺をこちらで保つ必要がなく、Queueryの構成をシンプル化できそうだということがわかりました。
ID 1のノードのcolumnは 0...23 となっていて、これは json[:articles][:title]という文字列全体の範囲に対応しています。この全体に下線を引くとどこでエラーが起きたかわかりにくいので、error_highlightはなるべくメソッド名の位置を特定して線を引くようにしています。大まかに言えば、レシーバの子ノードである ID 2のノードの終端より後、つまり [:title]の下にだけ下線を引くようになっています。
GroupieはRecyclerViewの実装を簡素化できるため縦一方向にスクロールするUIを構築する上ではとても便利です。しかし画面の一部でコンテンツが横並びするような表示が必要になった際にはRecyclerView in RecyclerViewな構成を避けることができず実装が複雑になってしまいます。
例えば以下のスクリーンショットではカルーセルのような表示のRecyclerViewと画面全体のRecyclerViewがネストした構成となります(矢印方向がRecyclerViewでの表示)。
以上の内容までがAfter Party DroidKaigi 2021で発表したものになります。その後クックパッドマートアプリでは上記方針で実際にGroupieからJetpack ComposeへのUI実装移行に取り組み、期待通りの開発体験の改善を得ることができました。
一方で実装移行を進めていくうちに移行作業の障害となる当初予想していなかった問題に直面しました。そのため現在はアプリのユーザービリティを最優先と考え、やむを得ず以下の方針で開発を行っています。
実装移行中の既存画面を一旦元のGroupie実装に戻してGroupieでの実装を継続する
新規の画面はJetpack Composeを使って実装する
これらの対応が必要となった主な問題を紹介します。
スクロールが引っかかる
画面をスクロール中にAndroidView in Jetpack Composeで構成されたGroupieItemに指が触れた際にスクロールが停止する挙動が見つかりました。最下層のAndroidViewにクリックイベントが設定されていた場合に再現し、focusableをfalseにするなど思いつく対策は試しましたが解決することはできませんでした。そもそもAndroidView in Jetpack Compose in AndroidView in RecyclerViewのような歪な構造になっているのが良くなく、スタンダードな実装からも外れているため将来的なJetpack Composeのアップデートでも改善は期待できないと思っています。
ary = [1, 2, 3]
val = 2# Ruby 3.0でも3.1でも動くin ary in [x, ^val, z]
p x #=> 1
p z #=> 3
end
# Ruby 3.1から書ける(かっこが必要)in ary in [x, ^(1 + 1), z]
p x #=> 1
p z #=> 3
end
# すでにマッチした変数パターン`x`を参照することもできるin ary in [x, ^(x + 1), z]
p x #=> 1
p z #=> 3
end
A command syntax is allowed in endless method definitions, i.e., you can now write def foo = puts "Hello". Note that private def foo = puts "Hello" does not parse. [Feature #17398]
p File.dirname('/home/ko1/foo.txt') #=> "/home/ko1"
p File.dirname('/home/ko1/foo.txt', 0) #=> "/home/ko1/foo.txt"
p File.dirname('/home/ko1/foo.txt', 1) #=> "/home/ko1"
p File.dirname('/home/ko1/foo.txt', 2) #=> "/home"
p File.dirname('/home/ko1/foo.txt', 3) #=> "/"
p File.dirname('/home/ko1/foo.txt', 4) #=> "/"
(ko1)
GCの実行時間を計測する新しい方法が追加された
"GC.measure_total_time = true" enables the measurement of GC. Measurement can introduce overhead. It is enabled by default. GC.measure_total_time returns the current setting. GC.stat[:time] or GC.stat(:time) returns measured time in milli-soconds.
GC.total_time returns measured time in nano-seconds. Feature #10917
ただ、GCの時間を正確に計測しようとすると、時間を測るためのオーバヘッドがかかってしまうため、GC.measure_total_time = trueのように、on/off の制御ができるようになっています。デフォルトは on です。つまり、遅くなります! が、ここのオーバヘッドが現実に効くようなケースは滅多にないだろうと思ってデフォルト on になっています。
Marshal.load now accepts a freeze: true option. All returned objects are frozen except for Class and Module instances. Strings are deduplicated. [Feature #18148]
data = Marshal.dump(obj)とすると、シリアライズされたデータを取り出せます。これを、Marshal.load(data)とすることで、Ruby オブジェクトに戻すことができますが、このときfreeze: trueというキーワード引数を加えることで、戻した Ruby オブジェクトを freeze することができるようなりました。
Marshalは、deep copyに利用することができることが知られていますが(文字列の配列の配列、みたいな場合、その文字列と配列を全部コピーするのがdeep copy)、この deep copy 時についでに全部 freezeしてまわることができます。
deffoo = :foo
p method(:foo).public? #=> false
p method(:foo).private? #=> true
チケットには pry とかで情報を表示するときに便利、ってありますね。自分は使うことあるかなぁ。
(ko1)
include済みのモジュールに対するprependが継承ツリーに反映されるようになった
Module#prepend now modifies the ancestor chain if the receiver already includes the argument. Module#prepend still does not modify the ancestor chain if the receiver has already prepended the argument. [Bug #17423]
include と prepend が混ざると混乱するんですが、これはそんな話です。
すでにクラス C に include されたモジュール M が別のモジュール P を prepend しても、Ruby 3.0 までは、C の継承ツリーに P は出てきませんでした。Ruby 3.1 からは、include されたモジュールに対しても P が出現するようになっています。
moduleP; endmoduleM; endclassCincludeMendM.prepend P
p C.ancestors
#=> Ruby 3.0: [C, M, Object, Kernel, BasicObject]#=> Ruby 3.1: [C, P, M, Object, Kernel, BasicObject]C.prepend P
p C.ancestors
#=> Ruby 3.0: [P, C, M, Object, Kernel, BasicObject]#=> Ruby 3.1: [P, C, P, M, Object, Kernel, BasicObject]
まぁ、難しいのであんまり多用しないほうがいいと思います。
(ko1)
privateやpublicなどのメソッドがシンボルなどを返値を返すようになった
Module#private, #public, #protected, and #module_function will now return their arguments. If a single argument is given, it is returned. If no arguments are given, nil is returned. If multiple arguments are given, they are returned as an array. [Feature #12495]
classC
p private(deffoo; end)
#=> Ruby 3.0: C#=> Ruby 3.1: :foodefbar; end
p private(:foo, :bar)
#=> Ruby 3.0: C#=> Ruby 3.1: [:foo, :bar]
p private#=> Ruby 3.0: C#=> Ruby 3.1: nilend
さらにメタプログラミングやっちゃうんですかね。
(ko1)
forkイベントをフックするためのProcess._forkが追加された
Process
Process._fork is added. This is a core method for fork(2).
Do not call this method directly; it is called by existing
fork methods: Kernel.#fork, Process.fork, and IO.popen("-").
Application monitoring libraries can overwrite this method to
hook fork events. [Feature #17795]
このコードは、Ruby 3.0ではキーワード引数から通常引数への暗黙的変換により Foo.new({foo: 1, bar: 2}, nil)のように解釈されてしまいます。
こういうコードを修正してもらうために、Ruby 3.1では移行措置として、動作自体は維持しつつ、警告を出すようになりました。
Foo.new(foo: 1, bar: 2)
#=> warning: Passing only keyword arguments to Struct#initialize will behave differently from Ruby 3.2. Please use a Hash literal like .new({k: v}) instead of .new(k: v).
String#unpack and String#unpack1 now accept an offset: keyword
argument to start the unpacking after an arbitrary number of bytes
have been skipped. If offset is outside of the string bounds
ArgumentError is raised. [Feature #18254]
Time.new now accepts optional in: keyword argument for the timezone, as well as Time.at and Time.now, so that is now you can omit minor arguments to Time.new. [Feature #17485]
Coverage measurement now supports suspension. You can use Coverage.suspend
to stop the measurement temporarily, and Coverage.resume to restart it.
See [Feature #18176] in detail.
# Ruby 3.0 (and works on 3.1)require'securerandom'
p Random.base64 #=> "cHn6rPPl75CwaTxNOL36tA=="
# Ruby 3.1require'random/formatter'
p Random.base64 #=> "mczNU8TeKq+ihK3p2e2hzw=="
(ko1)
■非互換
rb_io_wait_readable, rb_io_wait_writable and rb_wait_for_single_fd are
deprecated in favour of rb_io_maybe_wait_readable,
rb_io_maybe_wait_writable and rb_io_maybe_wait respectively.
rb_thread_wait_fd and rb_thread_fd_writable are deprecated. [Bug #18003]
これらの関数は deprecated になったようです。
(ko1)
■標準ライブラリの非互換
ERB.newの引数がキーワード引数のみになった
ERB#initialize warns safe_level and later arguments even without -w.
[Feature #14256]
ERB.newに普通の引数を渡すと、廃止予告の警告が出るようになりました。
# Ruby 3.1では警告が出るERB.new("src", nil, "%")
#=> -e:1: warning: Passing safe_level with the 2nd argument of ERB.new is deprecated. Do not use it, and specify other arguments as keyword arguments.# -e:1: warning: Passing trim_mode with the 3rd argument of ERB.new is deprecated. Use keyword argument like ERB.new(str, trim_mode: ...) instead.# キーワード引数渡しなら警告が出ないERB.new("src", trim_mode: "%")
Kernel#pp in lib/pp.rb uses the width of IO#winsize by default.
This means that the output width is automatically changed depending on
your terminal size. [Feature #12913]
o = Object.new
o.instance_eval dodeffoo = :fooend
p o.foo() #=> :foo
p foo() #=> undefined method `foo' for main:Object
これを実現するために、instance_evalを実行する前に毎回 singleton class を準備していたんですが、メソッド定義することって稀ですよね、だいたい self差し替えたいだけですよね、という知見から、本当に必要なときまで singleton class の生成を遅延するようになりました。メソッド定義を行わない場合に、instance_eval/execがすごく速くなったらしいですよ。
(ko1)
Structのアクセサを高速化した
The performance of Struct accessors is improved. [GH-5131]
Experimental feature Variable Width Allocation in the garbage collector. This feature is turned off by default and can be enabled by compiling Ruby with flag USE_RVARGC=1 set. [Feature #18045] [Feature #18239]
ここで生成されるコードは、aが 10 の時(Fixnumのとき)の特別なコードです。そのため、aが falsy だと、「コンパイルをやり直す」ということが起きます。アセンブラ中の je 0x5603e4bcd0a6、とか je 0x5603e4bcd0f1がそれにあたります(やり直すぞ、というところにジャンプしています)。
deffoo a
if a
a + 1elsenilendend20.times{|i|
p foo(i)
asm = RubyVM::YJIT.disasm(method(:foo))
if asm
puts asm
breakend
}
p foo(nil)
puts RubyVM::YJIT.disasm(method(:foo))
A new debugger debug.gem is bundled. debug.gem is a fast debugger implementation, and it provides many features like remote debugging, colorful REPL, IDE (VSCode) integration, and more. It replaces lib/debug.rb standard library.
rdbg command is also installed into bin/ directory to start and control debugging execution.
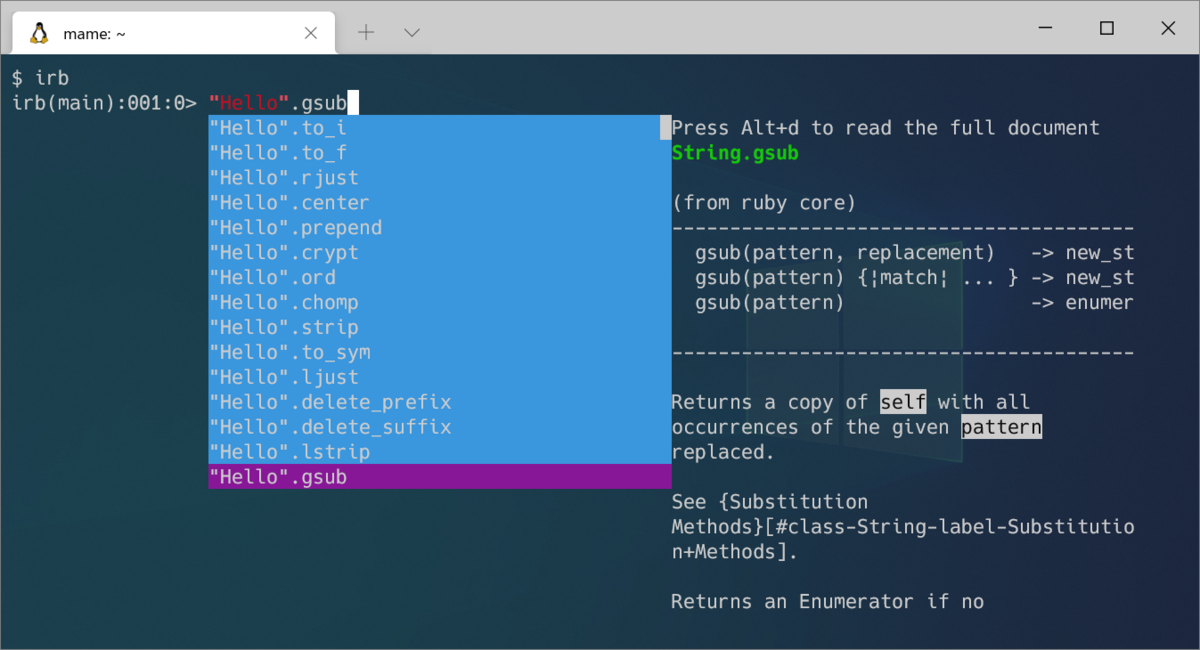
The IRB now has an autocomplete feature, where you can just type in the code, and the completion candidates dialog will appear. You can use Tab and Shift+Tab to move up and down.
If documents are installed when you select a completion candidate, the documentation dialog will appear next to the completion candidates dialog, showing part of the content. You can read the full document by pressing Alt+d.
lib/objspace/trace.rb is added, which is a tool for tracing the object allocation. Just by requiring this file, tracing is started immediately. Just by Kernel#p, you can investigate where an object was created. Note that just requiring this file brings a large performance overhead. This is only for debugging purposes. Do not use this in production. [Feature #17762]
$ ruby -run -e httpd
[2021-12-2120:25:28] INFOWEBrick1.7.0
[2021-12-2120:25:28] INFO ruby 3.1.0 (2021-11-17) [x86_64-linux]
[2021-12-2120:25:28] INFOWEBrick::HTTPServer#start: pid=105322 port=8080
[2021-12-2120:25:28] INFOTo access this server, open this URLin a browser:
[2021-12-2120:25:28] INFO http://127.0.0.1:8080
[2021-12-2120:25:28] INFO http://[::1]:8080
$ ruby -r debug app.rb
[1, 10] in app.rb
1| def fib n
2| if n <= 1
=> 3| debugger
4| 1
5| else
6| fib(n-2) + fib(n-1)
7| end
8| end
9|
10| p fib(10)
=>#0 Object#fib(n=0) at app.rb:3
#1 Object#fib(n=2) at app.rb:6
# and 5 frames (use `bt' command for all frames)
(rdbg)
(rdbg) bt # backtrace command
=>#0 Object#fib(n=0) at app.rb:3
#1 Object#fib(n=2) at app.rb:6
#2 Object#fib(n=4) at app.rb:6
#3 Object#fib(n=6) at app.rb:6
#4 Object#fib(n=8) at app.rb:6
#5 Object#fib(n=10) at app.rb:6
#6 <main> at app.rb:10
(rdbg)
$ rdbg app.rb
[1, 9] in app.rb
=> 1| def fib n
2| if n <= 1
3| 1
4| else
5| fib(n-2) + fib(n-1)
6| end
7| end
8|
9| p fib(10)
=>#0 <main> at app.rb:1
(rdbg)
(rdbg) b 3 # break command
#0 BP - Line /home/ko1/app/app.rb:3 (line)
(rdbg) c # continue command
[1, 9] in app.rb
1| def fib n
2| if n <= 1
=> 3| 1
4| else
5| fib(n-2) + fib(n-1)
6| end
7| end
8|
9| p fib(10)
=>#0 Object#fib(n=0) at app.rb:3
#1 Object#fib(n=2) at app.rb:5
# and 5 frames (use `bt' command for all frames)
Stop by #0 BP - Line /home/ko1/app/app.rb:3 (line)
(rdbg)
$ rdbg -A
[1, 9] in app.rb
=> 1| def fib n
2| if n <= 1
3| 1
4| else
5| fib(n-2) + fib(n-1)
6| end
7| end
8|
9| p fib(10)
=>#0 <main> at app.rb:1
(rdbg:remote)
SNS にシェアされたレシピがより魅力的に見えるようにしたいという思いと、クックパッドのレシピであることがひと目で伝わってほしいという気持ちから OGP 画像のデザインを変えられないかという話が挙がりました。開発はそれなりにかかりそうなので、まずはクックパッドの公式ツイッターアカウントから「画像ウェブサイトカード」(Twitter for Business の機能) を使って特定のレシピページに対して手作業で作ったいくつかのパターンの画像を当てて複数回プロモーションツイートを投稿し、パターンごとのエンゲージメント率などを見ながらどのデザインが良さそうかを検討しました。検証を経て現在のデザインに決まったので、次に実現方法の検討に移りました。
例えば、運用フェーズでも運用者に渡す前・渡した後にエンジニアが運用することがあり、自分たちで作った運用フローが業務を圧迫していないかや、事故を未然に防ぐことができているかなどを確認しています。 具体的には、実際に Live 配信の現場に立ち会って、急にトラブルが起きたらどうするかをイメージしてシステムを設計したり、 Live 配信中に大量に販売した商品を梱包して発送する作業をして、発送ミスが起きないようにするにはどういう仕組みが必要なのかを考えたりしています。
CookpadTV の開発スタイルでは、エンジニアが要件・仕様整理することが大小問わずあるので、上で述べたような事業の状況に合わせた判断が必要になるのですが、これを開発メンバー全員が行うのは無理があります。マネージャーとしては、いろんな情報をキャッチアップしておいて、できるだけこの判断がいい感じにできるように心がけています。 例えば、ユーザー向けの新機能は Live 配信の企画に沿って運用できるものになっているのかを配信ディレクターの様子から伺ったり、季節のイベントに合わせた大型企画を最大限成功させるためにできる工夫がないかを探ったり、トライアルに間に合わせるために作った暫定的なシステムを用意した時に発生しうるイレギュラー対応を先回りして仕組み化しておくべきものは無いかを探ったりしています。
例えば、「システム全体の設計するスキルを高める」という Will を持った人がいれば、その1年の山場となりそうなプロジェクトを任せる前に、早めに小さいプロジェクトから素振りをしてもらったり、「プロジェクトの管理をする」という Can を身につけて欲しい人がいれば、他部署の打ち合わせに同席してもらったりと、単純に他の人がやったほうが早いものであってもチームの成長・成果に合わせて仕事を設計しています。
これは結構大事だと思ってます。自分ができることは限られていますが、やれる範囲のことはなんとかするし、範囲外のことはどうしたら解決できるかを考えます。
Live 配信中に現場でトラブルが起きても、全然知らないシステムで大障害が起きても、自分の守備範囲外のスキルを持ったメンバーが辞めても、最後の砦としてやっていく気持ちが必要です。(でも実際は、真の最後の砦が後ろに何個かありますw) そういう気持ちで取り組んでいると自然と守備範囲が広がりますし、自分の成長にも繋がるし、チーム的にも強くなっていくはずです。
クックパッドスキルのデプロイという行為は、 PR のマージ後に走る CI と、その後にチャットボットを利用したデプロイコマンドの実行により上に述べたリソースを最新のものにアップデートし、必要に応じて審査にサブミットすることを意味します。
ここまでの説明だけを見ると、登場するリソースも少ないですし、ただ CI とチャットボットがあるだけで仕組みも非常に簡単そうに見えますが、 Alexa 固有の仕様によって工夫が必要な部分もいくつかありますのでここで紹介をしていきます。
Lambda 関数の管理について
スキルストアに公開されている Alexa Skill は、1 つのスキルに 2 つの実体が存在します。Live バージョンと Development バージョンです。
Live バージョンは名前の通り一般公開され実際に使用されているバージョンのスキルです。 Development バージョンはこちらも名前の通り開発用に使用するスキルです。
Live バージョンは基本的にデータの一切の変更が不可能です。開発者は Development バージョンのスキルに必要な変更を加え、審査に出し、パスすることで変更を Live バージョンに反映することができます。
以下の図が Development バージョンのスキルを審査に提出した際のフローになります。それぞれのバージョンが持つメタデータやバージョンの変化に対するの理解を簡易にするためにこのような書き方をしておりますが、実際の挙動は明らかではありません。
すなわち、図では Development バージョンのスキルが審査を経て新しい Live バージョンになっていますが、ただ単に Development バージョンのスキルのデータで Live バージョンのスキルを上書きしていることもありえます。
上記の図から以下のことが言えます。
Development バージョンのスキルは、少なくとも審査提出時には本番環境の Lambda 関数をエンドポイントに設定する必要がある
Lambda 関数に互換性の無い変更をする場合、審査に提出する Development バージョンのスキルは Live バージョンと異なる Lambda 関数を利用する必要がある
後者が少し厄介です。もう少し詳しく説明すると、例えば新しい発話への対応や、インタラクションフローの変更をする場合、 Live バージョンで利用している Lambda 関数と互換性がないため、異なるエンドポイントにコードをデプロイをし、それを Development バージョンのエンドポイントとして設定し、審査に提出する必要があります。