社内の API サービスは OAuth2 をベースとした自前の認証認可サービスで認証認可を行うことが一般的です。これらの API サービスに対して負荷試験を行う場合、アクセストークンをリクエストヘッダにセットしたり、アクセストークンの有効期限が切れていた場合にリフレッシュする処理が必要になります。Artillery には、リクエストの前後やテストシナリオの前後でフックする仕組みがあり、これを使ってアクセストークンのハンドリングを実装しました。
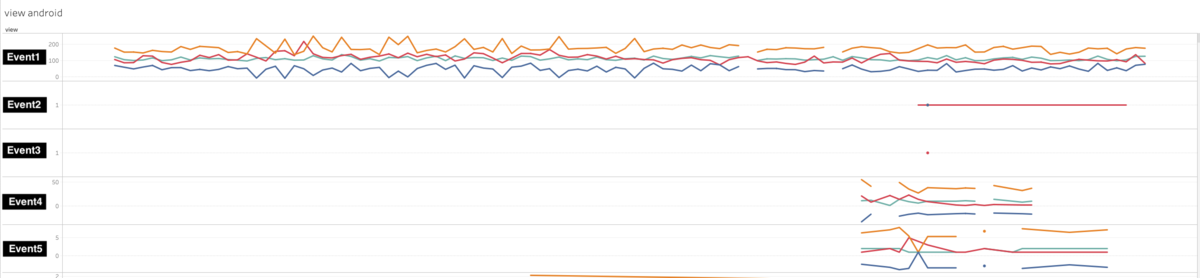
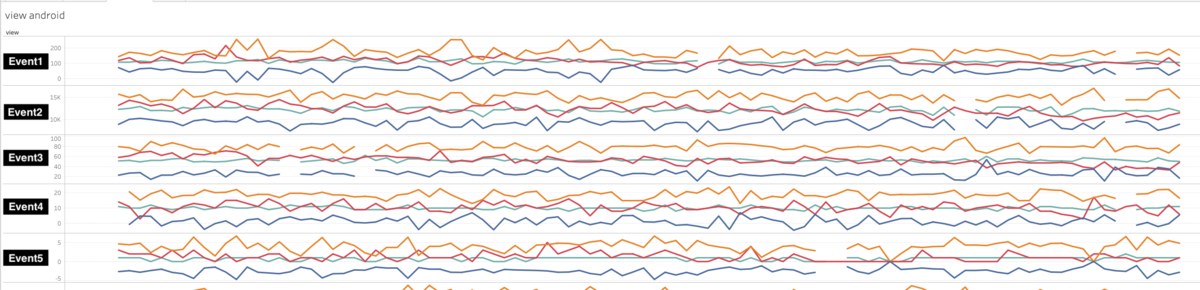
レシピサービスは社内で最も歴史のあるサービスで、内部のマイクロサービス化やリファクタリングは進んでいるものの、それ専用の仕組みがあったりと複雑な構成です。レシピサービスについて、専用の負荷試験環境を構築することは非常に難しく、また大きな労力がかかることは予想できたため、細心の注意を払いながら「本番環境」で負荷試験を行いました 1。テストシナリオは基本的に開発チーム側で準備してもらいつつ、レビューは SR グループでも行いました。負荷試験はテストシナリオを微修正しつつ何度か実行し、ミドルウェアのボトルネックなどいくつかの脆弱な箇所が洗い出されました。
サービス X の ECS サービスのスケーリングポリシーの最大タスク数に当たってしまい、リソースが不足しレイテンシが増加した。最大タスク数を引き上げた
サービス Y のバックエンド Elasticsearch が CPU リソース不足になりレイテンシが増加した。Elasticsearch の Data ノードのスケールアウト、N+1 クエリの解消、追加でレスポンスのキャッシュを実装が行われた
サービス Z のバックエンド MySQL が CPU リソース不足になりレイテンシが増加した。Z 内でのキャッシュの実装の見直しが行われ、さらに MySQL 接続ユーザやコネクション周りの設定不備も見つかった
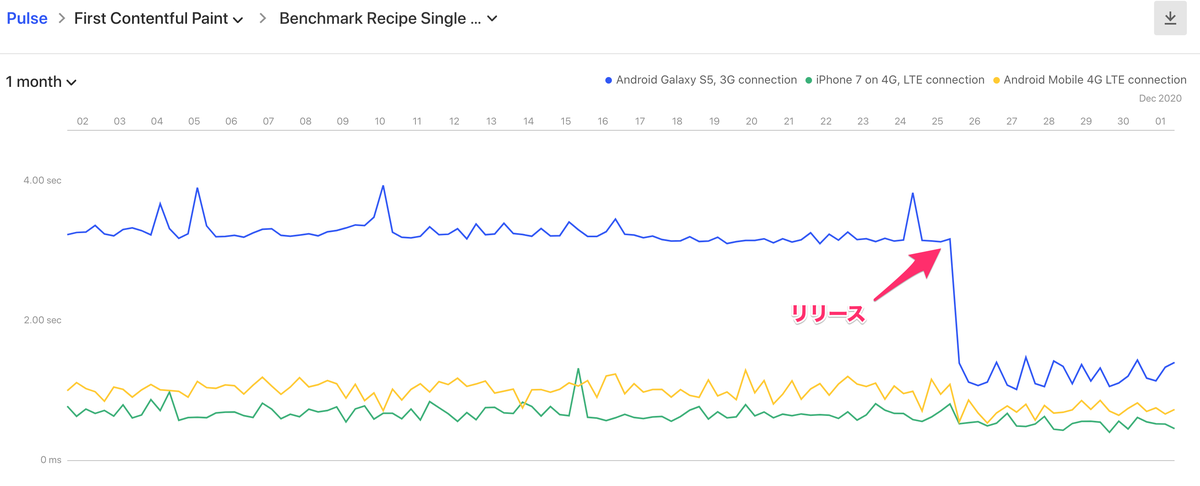
最初のうちは、開発チームと SR グループで一緒に負荷の見守りを行っていましたが、終盤はほとんど開発チームだけで負荷試験の実行や中断ができるようになっていました。結果的に想定のテストシナリオをすべてクリアし、キャパシティに自信を持って 100% リリースすることができ、キャパシティ起因の問題は発生しませんでした。本番環境での負荷試験は、それ自体が大きなテーマであるため、このエントリではあえて詳細を書いていません。近いうちに別のエントリとして公開したいと考えています。
社内での Web サービスの負荷試験について、現状と改善の余地を述べ、Serverless-artillery を使った負荷試験の検証、より利用しやすくするための Web コンソールの開発に至るまでを説明しました。開発した Web コンソールは、実際に数回負荷試験に利用されています。テストシナリオのレビューで SR グループが最初関わることもありますが、その後は開発チームがほとんど自分たちで負荷試験のサイクルを回せているという所感です。これ以外にも、負荷試験に利用できる周辺の仕組み2が整ってきており、負荷試験、さらにはキャパシティプランニングが開発において当たり前となっていくような開発体制になることを目指していきたいです。
また、今回コンセプトとして据えた「目を見て話せる」というのはキッチンで料理をするシーンでは微妙で、もう少し洗練させるか、もっと別の良いトリガーを考える必要があると感じました。
これもモバイル向け OS の画像認識ライブラリの性能や仕様によるところがあるため、例えばペーパープロトタイピングなどでは実感するのが難しく、実際に簡単なアプリケーションを作って料理をしたおかげで得られた収穫でした。
このように、技術的な検証を含む日常的なプロトタイピングにおいて、 Flutter を活用することでモバイル向け OS のアプリケーションを簡単に開発し、プロトタイピングすることが出来ました。 今後も、より多くのプラットフォームで動くようになることを期待しつつ、さまざまなプロトタイピングのシーンで活用していこうと思います。
解析結果をスタッフに利用してもらう方法として,データベースを利用せずに予測 API を用意する方法も考えられます.
今回のタスクの目標は「すでに投稿されたレシピからの料理用語の自動抽出」であり,これはバッチ処理であらかじめ計算可能です.
このため, API サーバを用意せずにバッチ処理で予測を行う方針を採用しました.
select
, s.recipe_id
, e.name
, e.category
from
recipe_step_named_entities as e
innerjoin recipe_steps as s on e.step_id = s.id
where
e.category in ('Tg')
and s.recipe_id = xxxx
$ allennlp --help
2020-11-05 01:54:24,567 - INFO - allennlp.common.plugins - Plugin allennlp_optuna available
usage: allennlp [-h][--version] ...
Run AllenNLP
optional arguments:
-h, --help show this help message and exit--version show program's version number and exitCommands: best-params Export best hyperparameters. evaluate Evaluate the specified model + dataset. find-lr Find a learning rate range. predict Use a trained model to make predictions. print-results Print results from allennlp serialization directories to the console. retrain Train a model with hyperparameter found by Optuna. test-install Test AllenNLP installation. train Train a model. tune Optimize hyperparameter of a model.
最適化したいハイパーパラメータを local lr = std.parseJson(std.extVar('lr'))のように変数化しています.
std.extVarの返り値は文字列です.機械学習モデルのハイパーパラメータは整数や浮動小数であることが多いため,キャストが必要になります.
浮動小数へのキャストは std.parseJsonというメソッドを利用します.整数へのキャストは std.parseIntを利用してください.
2017年以前クックパッドアプリにはアーキテクチャと呼べるようなものが存在していませんでした。大まかに API 通信や DB 操作等のデータ取得箇所を分離し、複雑なロジックを持つ場合は Manager, Util 等の強いオブジェクトが生成されていましたが、それ以外は Activity / Fragment に処理を直接記述することがほとんどでした。
Go で言われているらしい "Do not communicate by sharing memory; instead, share memory by communicating."ということですね。Go と異なるのは、Go はいうてもメモリをいじってコミュニケーションできてしまう(メモリを共有しているので)のですが、Ractor ではコピーしちゃうので、そもそも共有ができません。Go は「気をつけようね」というニュアンスですが、Ractor では「絶対にさせないでござる」という感じです。
ちなみに、何かのカウンタなら多少の誤差は許されることもあるかもしれませんが、例えば STM でよく例に出てくる銀行口座の残高の移動というタスクにおいては大問題になってしまうかもしれません。例えば、A さんから B さんに n 円送金するとき、A さんから残高を減らして、B さんに残高を追加する、という処理になります。このとき、Aさんから残高を減らしたタイミングで他の Ractor から A, B 各氏の口座が観測され、世界から n 円消える、という瞬間を目撃していまいます。それはまずい、あってはならないことです。
読み込み時には、トランザクションログにその TVar の書き込み履歴があれば、Ractor local なその最新の値を返し、なければ読み込む。このとき、TVar に記録された最終書き込み時間と、開始時に記録した T を比較し、T が古ければればロールバック。新しければ読み込み完了だが、ついでにトランザクションログに載せておく(次の read 時は、TVar を読む必要がなくなる)
(3) コミット
コミット時、トランザクションログに記録された TVar たちについて、最終書き込み時間が T より新しくないことを確認
時刻を1進める。この時の時刻を T'とする。
書き込みが必要な TVar には、変更を反映。このとき、その TVar の最終書き込み時間が T'となる。
② 特定の使い方を探している人向け 特定の使い方を探している人はある程度メンタルモデルが構築されています。なので「こういうことをするには、多分こういう機能がありそう」と思いながらドキュメントを読み始めます。よって「こういうことをするには」に相当するような「よくあるユースケース」や「サンプル集」を用意するのが良いでしょう。
③ もっと使いこなしたい人向け こういう人はメンタルモデルがバッチリ構築済みなので、網羅的なドキュメントを用意するのが良いでしょう。いわゆる「リファレンス」や「辞書」みたいなものです。一つ気をつけるべきアンチパターンは「APIリファレンスしか用意されていないライブラリのドキュメント」みたいなものです。これは「もっと使いこなしたい人向け」以外の読者のメンタルモデルや目的を完全に無視していると思います。(それで問題ない場合ももちろんありますが)
さらに「時間余ったからせっかくなんで日本語版も撮ろうか?」みたいな話になり急遽日本語版も撮影することになりました。過去のThis is My Architectureをざっと見た限り二ヶ国語で別々に撮影されたものはほぼ無さそうで、おそらくかなりレアケースだったようです。おかげで日本語版も撮影させてもらったのですが、それまでずっと英語で話していた内容で全く日本語版を想定していなかったので、撮影中は必死に英語から日本語に翻訳して喋っていました。
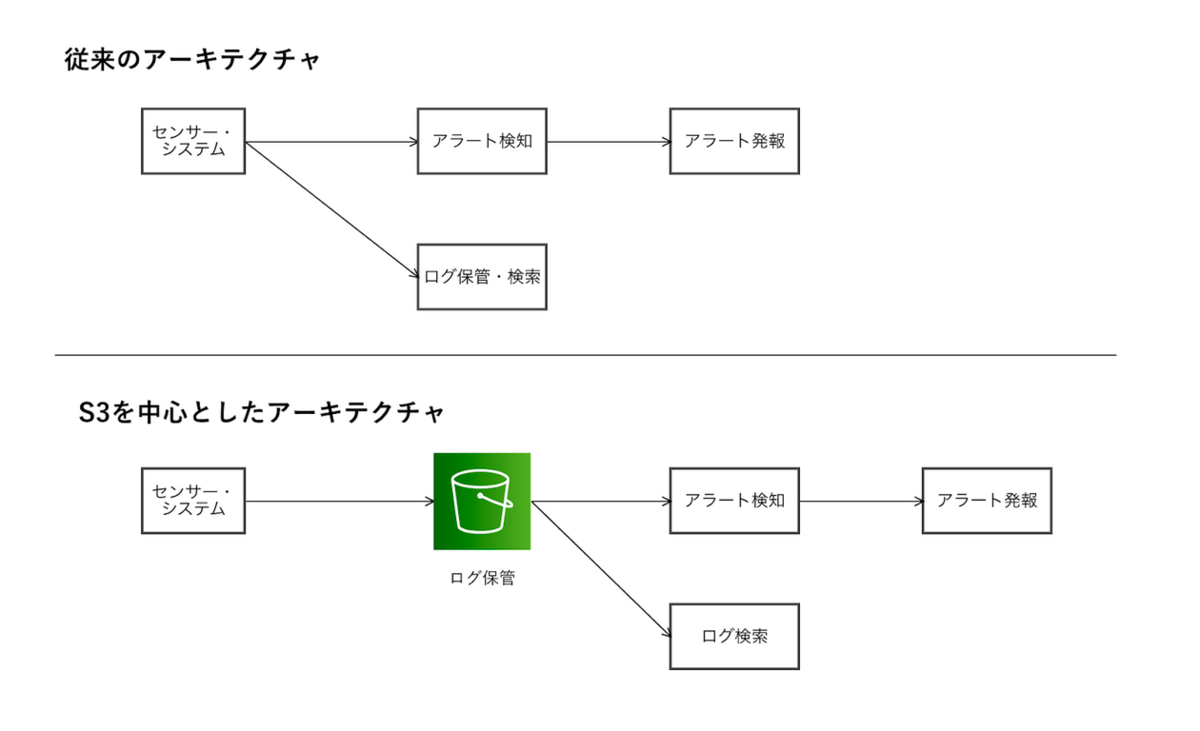
従来、セキュリティ関連のログ管理ではSIEM(Security Information & Event Manager)などのログ管理ソリューションが用いられて来ました。細部は製品やサービスによって違うものの、大まかな発想としてはログを直接取り込んでアラートを検出するフローとログを保管するフローを別々に扱うものが多かったと思います。このアーキテクチャの利点は、取り込んだログをなるべく早くアラート検知に利用することで発報までの遅延が短くなることです。しかし一方で以下の2つの課題を抱えています。
少し話が変わりますが、クックパッドのセキュリティエンジニアはこのような自分たちが必要とする仕組みを自分たちで考え、組み立て、現場に活かしていくというのが役割の一つになっています。先日、CODE BLUE 2020でもこのような話をさせていただいたのですが、情報セキュリティの課題を知識や経験だけでなくエンジニアリングで解決していく、というのはとても刺激的で、私自身はとても楽しんで仕事をしています。しかし現状、一緒にチャレンジしてくれるメンバーが足りていないこともありセキュリティエンジニアのポジションは引き続き募集しています。もし興味のある方がいらっしゃいましたら、まずはzoomなどでカジュアル面談して実際どうよ?という話もできるかと思いますので、ぜひお気軽にお声がけください!
ShapeableImageViewも Material Components を導入したおかげで使えるようになったView要素です。
Shape による画像の切り抜きや枠線をつけることができる ImageViewで、これまで Glide でやっていた処理をレイアウト側の定義だけで行えるようになりました。
画面実装ドキュメント整備
Material Components の導入による画面実装の変化やリニューアル実施前の相談によって決まった画面実装方針についてドキュメントをまとめました。
今回のリニューアルプロジェクトではAndroidアプリをこれまで開発していなかったメンバーも開発に参加することになったため、初学者にもわかりやすい内容と公式へのリンクをまとめました。
この内容については吉田さんが後日techlifeに記事を書いてくれる予定なので、主な内容だけ列挙しておきます。
# test.rbdefhello_message(user)
"The name is " + user.name
enddeftype_error_demo(user)
"The age is " + user.age
end
user = User.new(name: "John", age: 20)
hello_message(user)
type_error_demo(user)
Important: MATCH_PARENT is not recommended for widgets contained in a ConstraintLayout. Similar behavior can be defined by using MATCH_CONSTRAINT with the corresponding left/right or top/bottom constraints being set to "parent".
まず本当に異常検知すると嬉しいのかどうかを半信半疑になって確認する必要があります。ログの異常検知をすると決まった時点で、DWHに蓄積された各種ログの集計内容を監視して上振れ・下振れなどの変化を監視することは決定していました。ただし、この時点では変化点検知(change point detect)か外れ値検知(outlier detect)かはまだ決まっていません。
冒頭にも書きましたとおり今年の re:inventでAWSからAmazon Lookout for Metricsが発表されました。こちらはまだプレビュー版ですが、今回作った異常検知フローをそのまま置き換えることができるかもしれません。幸いにして今回のフローはアルゴリズムやチューニングに注力することなく、最小の労力をもって「ログの品質を保つためにはどんな仕組みが必要となるか?」の模索した解決案の一つに留まっていました。このため最終的な唯一の課題解決手法ではなく、むしろ課題を理解するためのプロトタイプに近く、実際に運用してみることで品質維持のために求められる多くの要素を知ることができました。